
NVIDIA pokazała nowy układ graficzny H100 oparty na architekturze Hooper

NVIDIA nie próżnuje i w trakcie konferencji wygłoszonej na targach GTC 2022 zaprezentowała nowy akcelerator graficzny H100 oparty na architekturze Hooper. Potężny układ trafi co prawda do maszyn serwerowych, ale na jego przykładzie możemy śmiało ocenić, jak będzie wyglądała kolejna generacja kart graficznych do komputerów stacjonarnych i laptopów. Oficjalnie zatem Hooper zastąpi Ampere, czyli dotychczas wykorzystywane jednostki.
Nazwa pochodzi od kobiety bardzo zasłużonej w inżynierii informatycznej - Grace Hooper, zatem podkreśla niezwykłą personę. Układy zaprojektowano z myślą o rozwoju sztucznej inteligencji, szczególnie na potrzeby wewnętrznych usług, ale też stale rosnących wymaganiach rynku pojazdów w pełni autonomicznych. NVIDIA wykorzystuje elementy SI do swoich niesamowitych technologii, a uczenie maszynowe wspiera działanie techniki DLSS o której wielokrotnie już pisałem na naszych łamach.
Architektura Hooper jest dosłownie szalona i zarazem najpotężniejsza na rynku




NVIDIA zapewnia, że nowe układy zagwarantują największy skok wydajnościowy i technologiczny w całej historii firmy, a to już bardzo odważne słowa. Hooper korzysta z niestandardowego procesu litograficznego TSMC N4 (4 nm), a karty wylądują na złączach serwerowych SXM5 oraz dużo bardziej powszechnych i konsumenckich PCI-E 5.0, gdy te wreszcie trafią na rynek i zastąpią kompletnie niewysłużone PCI-E 4.0. Stara wersja będzie rzecz jasna dalej wykorzystywana, ale zmiany były widocznie konieczne, skoro premiera następcy szykowana jest w tak krótkim czasie. Nowe złącze gwarantuje dwukrotny wzrost przepustowości - aż 128 GB/s, zamiast 64 GB przy PCI-E 4.0.

Ponadto układ H100 zbudowano z aż 80 miliardów tranzystorów (dla porównania, jego poprzednik A100 miał 54,2 mld), a wersja przeznaczona na rynek specjalistyczny i serwerowy, oparta na złączu SXM5 skorzysta ze 132 bloków SM. Wariant przeznaczony dla PCI-E 5.0 został delikatnie okrojony do 114 bloków, co przekłada się na 14592 procesory strumieniowe. To ponad dwukrotnie więcej od poprzednika - A100, który dysponował 6912 jednostkami. Wzrosła też nieznacznie liczba rdzeni Tensor, do 456. Wariant dla złącza SXM5 ma z kolei 16896 procesorów strumieniowych i 528 rdzeni Tensor 4. generacji, dysponując teoretyczną mocą na poziomie 60 TFLOPSów (w FP32). Nie zabrakło też 80 GB pamięci HBM3 o przepustowości 3 TB/s i 5120-bitowej szynie (!), ale tylko dla wariantu na SXM5. Dzięki zastosowaniu połączenia NVLink można osiągnąć przepustowość na złączu na poziomie 900 GB/s. Konsumenckie PCI-E 5.0 gwarantuje, jak wyżej wspominałem, "tylko" 128 GB/s. Różnica jest kolosalna, ale ma to przełożenie wyłącznie przy zastosowaniach profesjonalnych i w potężnych serwerach/stacjach roboczych.
Wiadomo również, że nowy akcelerator H100 będzie mieć TDP na poziomie sięgającym nawet 700W, czyli blisko 300W więcej od swojego poprzednika. Będzie zatem wymagał znacznych inwestycji w nowe układy chłodzenia, które zdołają odprowadzić ogromne ilości ciepła z procesora. Wzrosty wydajności będą jednak spektakularne, szczególnie przy działaniach związanych ze sztuczną inteligencją. Tutaj, dzięki zastosowaniu nowych rdzeni Tensor 4. generacji, pewne obliczenia będzie można przeprowadzić nawet kilkukrotnie szybciej. Układy z rodziny Hooper będą wspierały także elementy dynamicznego programowania z wykorzystaniem rekurencji i memoizacji. Pierwsza z funkcji pozwala rozbić zadanie na drobne podzadania, co pozwoli zaoszczędzić moce obliczeniowe. Druga odpowiada za przechowywanie gotowych już rozwiązań powstałych po wykonaniu obliczeń, które będzie można dynamicznie wykorzystać do szybszej pracy w przyszłości. Napisałem to w bardzo uproszczony sposób, ale zasada działania sprowadza się do dużo wyższej efektywności. Do tych technik wykorzystane zostaną też nowe instrukcje DMX, które doskonale wiedzą jak radzić sobie z dynamicznym programowaniem.
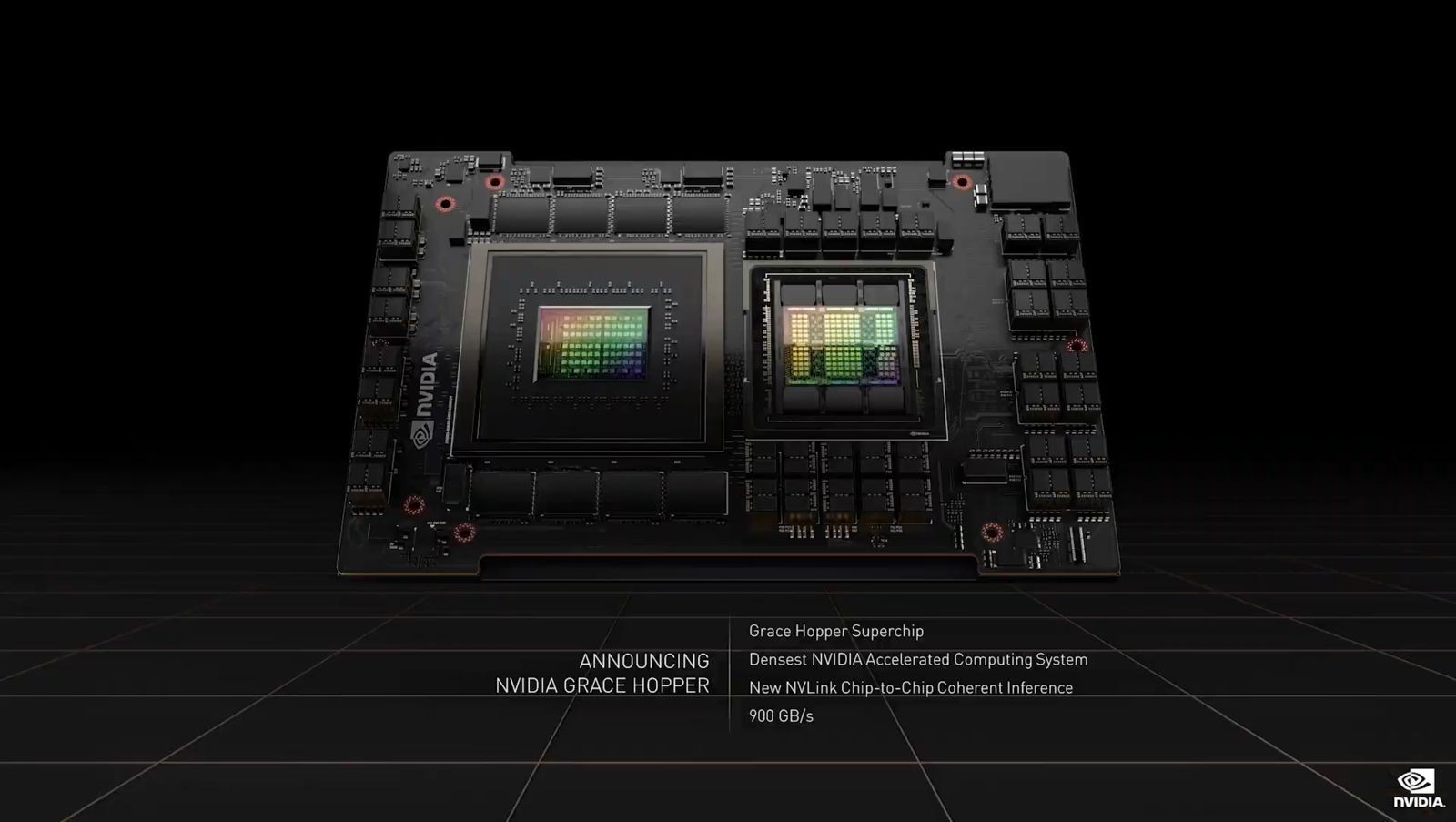
Nie zabrakło usprawnień dot. bezpieczeństwa, a akceleratory Hooper będą wyposażone w specjalne jednostki, które zagwarantują jeszcze wyższy poziom ochrony danych. NVIDIA pokazała też jednostkę DGH X100 złożoną z 8 kart H100, oferujących aż 640 miliardów tranzystorów i 32 PTFLOPy ogólnej mocy obliczeniowej dla sztucznej inteligencji. Daje to w rezultacie wielokrotnie wyższą moc względem poprzednich kart A100, przyspieszając obliczenia nawet kilkukrotnie. Doprawdy niezwykły pokaz mocy. Podczas konferencji pokazano też projekt nowej stacji roboczej wyposażonej w kombinację procesora i układu graficznego z rodzin Grace i Hooper. Żeby lepiej zobrazować przeskok wydajnościowy względem ubiegłorocznej jednostki, amerykanie wykorzystali testy w oprogramowanio SPECrate, gdzie skorzystano z nowych procesorów ARM wyposażonych w 144 rdzenie Neoverse. Końcowy rezultat wskazał 740 punktów, a więc blisko 2,5x więcej. Wystarczyło tylko 12 miesięcy, by pokazać światu ogromny progres.
Chociaż wszystkie powyższe informacje dotyczą wyłącznie układów wykorzystywanych w zastosowaniach profesjonalnych, możemy podejrzewać, że nowe karty graficzne z rodziny RTX 4000 dosłownie zwalą nas z nóg. Także wykorzystają nową generację rdzeni Tensor i będą jeszcze lepiej radzić sobie w obliczeniach związanych z ray-tracingiem. Być może zagwarantują też wyższą wydajność DLSS. Nie ulega wątpliwości, że będą miały olbrzymie zapotrzebowanie na prąd, ale rozwój technologiczny rządzi się swoimi prawami. Pierwsze informacje o konsumenckich jednostkach powinniśmy usłyszeć bliżej wakacji, a premiera spodziewana jest na przełom III i IV kwartału 2022 roku. Zobaczymy, co przyniesie przyszłość.

Przeczytaj również

![GTA 6 a pudełko z płytą na PS5 i XSX. Zdradzamy szczegóły tej wersji [AKTUALIZACJA - ROCKSTAR POTWIERDZA]](https://pliki.ppe.pl/storage/12877c1322fb12fcce72/12877c1322fb12fcce72.avif)




Komentarze (72)
SORTUJ OD: Najnowszych / Najstarszych / Popularnych